
Today I learned about Image Captioning using Tensorflow. The guide from the TensorFlow 2.0 Learning Directory and it is inspired from the Show, Attend and Tell: Neural Image Caption Generation with Visual Attention paper written by Kelvin Xu from Cornell University. We will be using the COCO database which contains large-scale object detection, segmentation, and captioning. The dataset is 13GB total and requires about 37 minutes to download so be prepared to grab a coffee while it downloads.
My thoughts on the Guide:
I am running this lab using the Colab provided by google (Mostly so I don’t have to download the gigantic dataset on my own computer lol)
To begin we use the InceptionV3 (pretrained on ImageNet) like we used in TensorFlow Flowers as a base then train the images with the COCO dataset.
Tokenizing the captions is a really interesting concept. Converting the Text to numbers and scrubbing to remove punctuation is used a lot because neural networks can’t comprehend text.
The Model is made using the model architecture inspired by the Show, Attend and Tell paper. which is basically extracting features from the lower convolutional layer of InceptionV3 and squashing the shape to fit in a CNN Encoder.
To Train we take the CNN Encoder output and pass it into a decoder and use teacher forcing to decide the next input to the decoder. Teacher forcing is the technique where the target word is passed as the next input to the decoder. Then we calculate the gradients and apply it to the optimizer and backpropagate as written in the Show, Attend and Tell paper.
The evaluate function is similar to the training loop, except we don’t use teacher forcing. The input to the decoder at each time step is its previous predictions along with the hidden state and the encoder output. Stop predicting when the model predicts the end token and store the attention weights for every time step.
An Example with a man trying to hit a baseball is below:
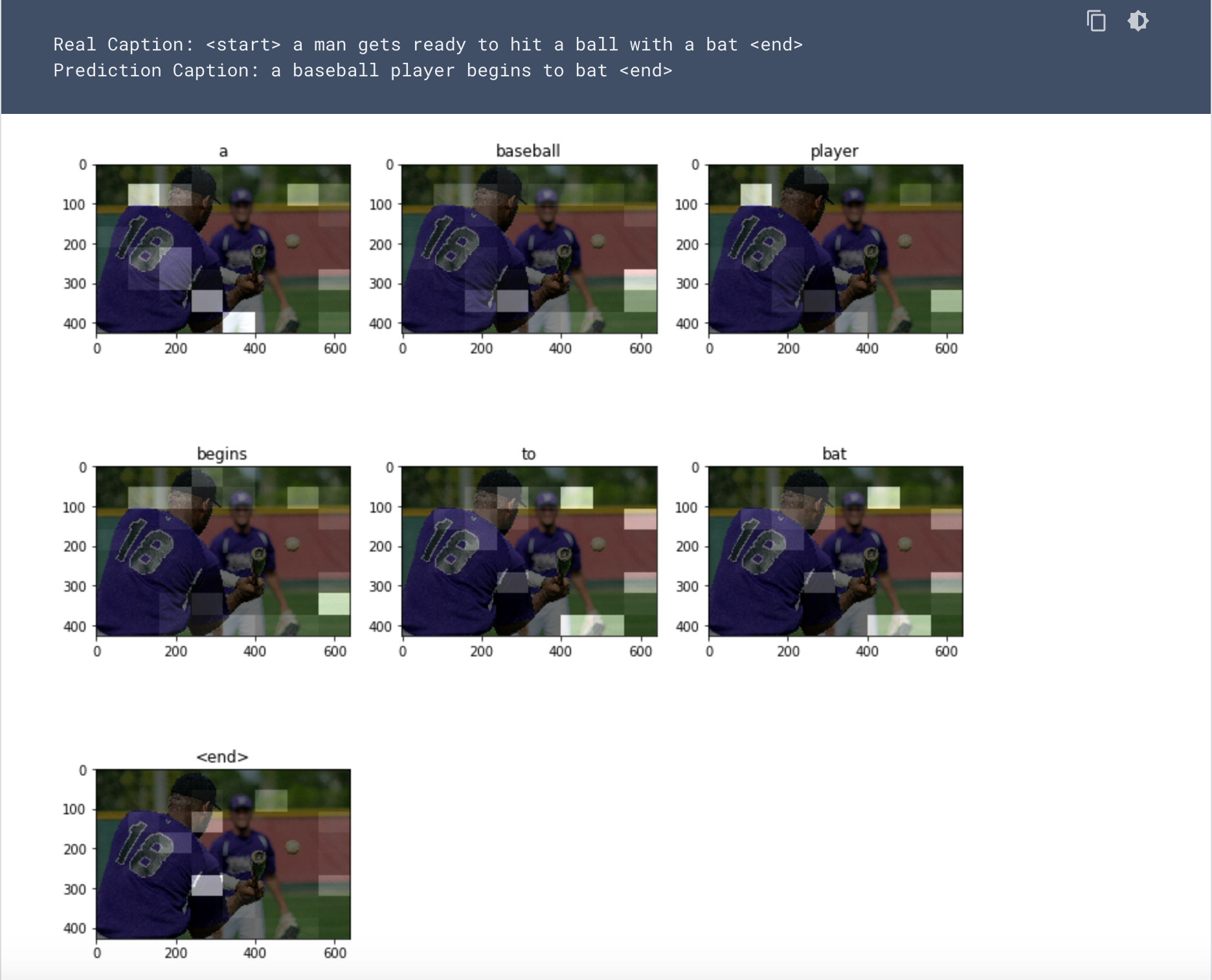
This guide for me was hard to follow. Mostly because I picked a module that I thought was interesting rather than the next module in difficulty. Overall, I learned a lot but felt it was challenging to fully comprehend most of the information. My hope is to use this post as a point in my life I can go back to and relook at the guide once I have more knowledge of the classifiers used. Specifically, Teacher forcing.
Sources
Xu, et al. “Show, Attend and Tell: Neural Image Caption Generation with Visual Attention.” ArXiv.org, 19 Apr. 2016, arxiv.org/abs/1502.03044.
